
Tl;dr WebSemaphore is a SaaS providing a serverless variation of the semaphore pattern, optionally coupled with a queue. The basic application is to allow exclusive/limited concurrent access to a resource. Using the builtin queue unlocks controlled, optimized throughput and lossless communication. Advanced features include on-the-fly configuration/capacity adjustment, temporary suspension, real-time monitoring and more.
Using its simple REST API it is easy to implement WebSemaphore into any system with minimal effort. If all of this is clear and you are already excited, head straight to the docs to get started. Otherwise, read on.
Table of contents:
3. Limitations and implied requirements
3.2 Summary - Implied Requirements
4. Infrastructure and capabilities
6. Scrutiny and alternative approaches
7. Conclusion and a generalization
0. Intro and disclaimers
This article is focused on an illustrative use case that inspired the conception and development of WebSemaphore.
We start with a problem statement and some requirements and then dive into specific architecture and scalability issues. There is little to no treatment of many key concepts such as security, testing, scrum, team management or politics.
Familiarity with event driven architectures, serverless/IaC is assumed, particularly basic understanding of AWS services.
Hopefully, the challenges discussed are universal and of interest to a wider community of integration architects, solution designers, cloud engineers and developers.
1. The use case
Recently, I had the privilege to contribute to a large-scale enterprise integration project for a global Pharma customer, taking on the technical architect/lead role.
The goal was deceptively simple: move all their Salesforce CRM data over into an Oracle DB instance within an internal AWS account. The system should operate in three modes: near real-time, scheduled and on-demand.
The reason to do this in the first place is also simple. Analytic jobs on Salesforce are too expensive even for a corporation. The solution is to mirror all data over to an internal database and have any query run for the cost of db operation.
The project aimed to replace an existing Mulesoft Anypoint-based prototype. The latter in its turn was an attempt to replace a functioning Informatica-based integration. Both previous solutions turned out to be too expensive and provided no real-time features. Instead, they synced nightly, meaning all data was at least a few hours old at all times during the day. This is not necessarily a problem as compliance rules often allow data reconciliation within 24 hours. But users of downstream systems would always have to account for the potentially outdated data.
The requirement was to deliver a purely serverless, AWS based implementation. It was expected to be a few times cheaper in operation and add near real-time processing as an additional benefit.
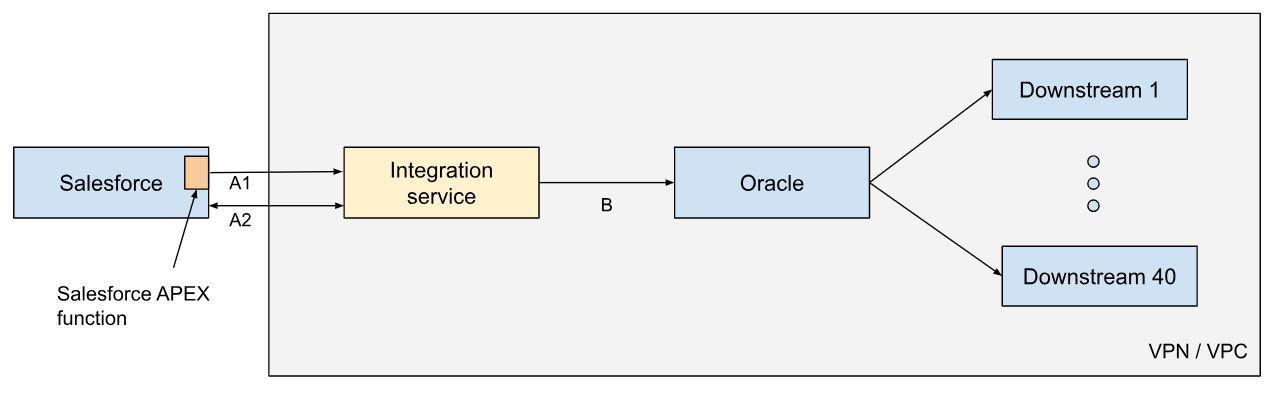
Fig 1. Corporate reducing the cost of its cost reduction solution. The replaced solution in the story is the yellow box. The orange box on the left is a part of the new, AWS-based solution.
To summarize - in order to reduce the costs of analytics within Salesforce there was a solution to move the data over to Oracle, and its costs were ridiculous. A Mulesoft pilot turned out to also be too expensive. The AWS project under discussion aimed to replace both.
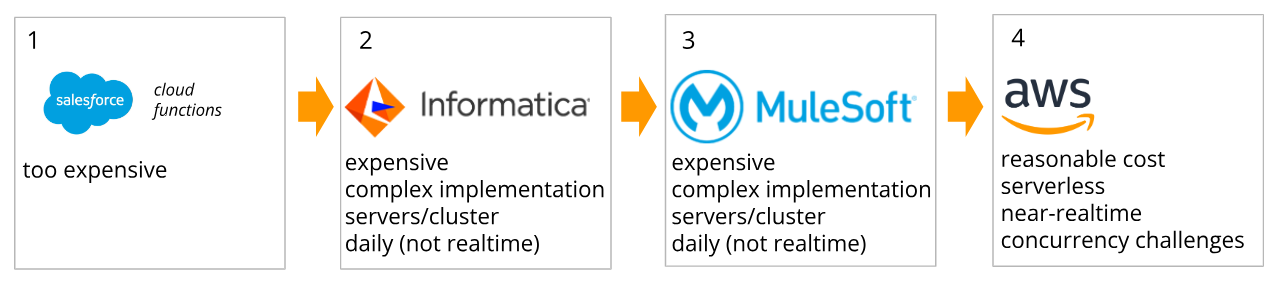
Fig 2. A long journey to cost reduction
Scope and target markets: The integration spans all countries in three global regions (Asia-Pacific, Americas and Europe - a typical technical/operational segmentation of the world by proximity). This includes pretty much every country in existence. It syncs all of the 230+ object types used by the company in Salesforce. About 85% of these objects are “standard” (treated and mapped almost identically) and the rest are split into a number of categories of exceptions requiring special treatment or mapping. The count of downstream systems is approximately 40. Traffic is generated by sales and marketing-related activities during business hours and therefore is proportional to the number of healthcare professionals (mostly doctors, nurses and pharmacists) in any given country. Traffic volume would measure in hundreds of thousands if not millions of events daily. Spikes are expected during marketing activities such as large events or high volume campaigns.
Despite the somewhat large numbers, the diagram in Fig 1 looks relatively uncomplicated and should be easy to implement, right? Right?!
2. The challenges
There are four categories of challenges causing technical complexity in this story:
- Corporate policies, compliance laws and other regulations. Things that are given and feel like gravity. It’s possible to cut a corner at times but mostly we just have to comply.
- Direct project requirements such as given above.
- Limitations and implied requirements - things under the surface of things. This includes e.g. security, data consistency and my favorite category - the unknown unknowns.
- Infrastructure and capabilities - the tools and services available (or missing) in the project environment to overcome the three challenges above.
Let’s do away with #1, since these are simultaneously situation-specific and unavoidable. Corporate processes are similar in a way and different in multiple ways but ultimately must be handled by the staff on the ground. Setting up twelve new environments in four new AWS accounts for the project, configuring permissions and piercing through the DMZ/firewall boundaries to allow Salesforce invoke our service is a bureaucratic song of ice and fire that saw sprints turn into months and could make its own story, but not this one.
The high level details for #2 were given in the previous section.
Which leaves us with #3 and #4 being the relevant parts.
3. Limitations and implied requirements
One term to be defined before we start is a stream. In the following sections a stream is a combination of a country code and a Salesforce object type, such as UK_Account or FR_Event. Each incoming event belongs to exactly one stream. Note that multiplying the number of countries by the number of object types, we arrive at tens of thousands of such streams.
The rest of the discussion should be understandable in a generic context.
3.1 The Details
Warning: technical details and jargon ahead. You will miss out on much of the fun, but may find it easier to jump to the next section (3.2) and return here if you are curious.
- Reading from Salesforce
After multiple reviews, including consultations with Salesforce architects, the winner for the most cost efficient option was identified. Activity in Salesforce would invoke platform events that kick off an APEX function (a kind of lambda in Salesforce) that makes an HTTP call to invoke our inbound flow (transition A1 in Fig 1). The messages in the call include only basic information: object type, country and the time the event was sent. To get the actual data, we query Salesforce via its standard SOAP API for the period between the most recent preceding synchronization and the time in the new incoming message (transition A2).
Thus, we get a request, check our notes for when the last sync occurred and pull the changes between then and the time in the request. This way we get full time coverage for all streams while not making any redundant requests. Note we avoid the capacity waste of polling. Instead, we are querying once we get notified there’s something for us on the other side, while making sure we did not miss any time slice.
Can we simply process the jobs as they arrive? Not exactly. Imagine we sync the time slice t1=[8:00,8:10) and in the meantime we receive a notification for an event at 8:11 that will cause us to sync t2=[8:10,8:11). If t1 is dense due to a traffic spike, and t2 contains only a few events, t2 will be processed faster, the write operations will go out of order and old data will likely overwrite new data causing more severe inconsistency than if t2 data was delayed.
Which implies the requirement: reads in every stream must be completed in the same order they arrived.
The time to perform these reads depends on the traffic volume at the moment. Notably, (1) Since jobs must be executed exclusively and in order, we can optimize by accumulating all messages belonging to a given stream that arrive while a job on that stream is in progress. We then pull all accumulated changes for the period in the next job, saving time and bandwidth while increasing the duration of an individual job. (2) Following an outage, the data may end up containing updates over hours or days in extreme cases.
Therefore, the read operation can take time sufficiently long to spill over the 15 minutes lambda execution time limit.
Conveniently, the Salesforce API is responding to queries in batches of 200 items, and we resort to AWS stored procedures to loop over multiple consequent batches of a single read.
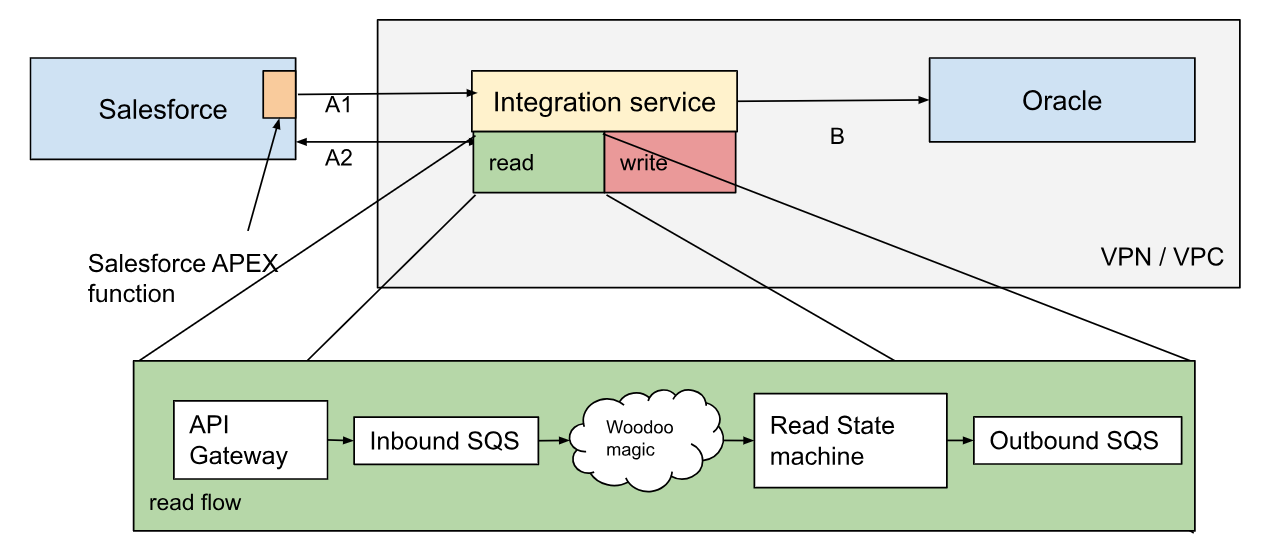
Fig 3. The inbound flow
- Writing to Oracle
What seems like an innocent SQL write operation turns into a development epic by virtue of the fact that upserts are not trivial with Oracle (and many other major RDBMS).There must be a temporary or permanent table containing the entries in question to enable a quirky conditional query that updates or creates items in the target table based on whether they exist. If you're curious, check places like this stackoverflow or google for “oracle upsert”.
As a result of the above and even more quirky Oracle internals it was deemed that writing to Oracle for the same stream simultaneously is going to break the consistency of written data and/or potentially cause a db deadlock at table level.
Which caused the implied requirement: updates must be queued and performed sequentially and exclusively per stream.
A major outcome of the above is that the upsert operation becomes a multistep flow wherein we clear the old landing data for a stream, download the new data into a blank state and finally perform the upsert into the target table. Since these are proportional to the size of the batch being written, we again opt for stored procedures to have flow guarantees and if necessary loop to avoid hitting the 15 minutes lambda execution time limit.!
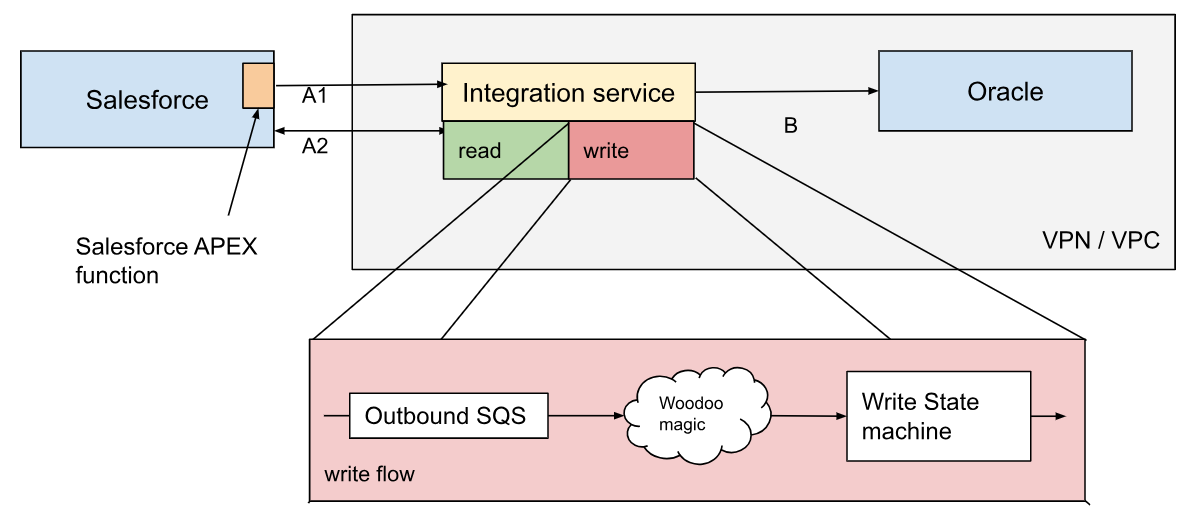
Fig 4. The outbound flow
- Limiting maximum throughput
At some point quite far into the prototype, the project owner casually asks whether we have a way to limit the number of concurrent connections to Salesforce. Turns out, every user is a license that has its limits and licenses are expensive. Duh.
The answer at that point was no. Resolving the previous two points would make every stream process sequentially, but not imply limits across streams. The number of streams is in the tens of thousands and processing them simultaneously during an activity peak will easily cross the overall cap. Incidentally, there are more AWS-specific limits this could hit, such as max concurrent lambdas per account-region.This prompted me to double check the limits on concurrent Oracle connections. Even though the Salesforce limit is clearly lower (3rd party vs a database in an internal AWS account), Oracle, and RDS in general, do have their concurrent connections limits.
Thus a new requirement was born: The number of simultaneous jobs must be limited to independently configurable maximums for both the read and write components.
4. Failure tolerance / Disaster Recovery
We must be conscious of processes failing, lambdas and networks going down any time and data centers going off-grid with no prior warning.
Two key decisions were taken in this respect (1) Handle low-probability events using SOP (service operating procedures). Essentially, this means a support team handling inconsistencies. (2) Stop processing any stream that cannot be recovered until explicitly reconciled and restarted by the SOP, but continue ingress for recoverability.
3.2 Summary - Implied Requirements
The points above are rich in detail and I wouldn’t blame you if you skimmed or skipped over them. They are given to establish a basis for the implied requirements summarized next:
3.2.1 Flow consistency: State machines are to be used for both the read and write flows to ensure strict execution/failure control and enable looping for jobs that exceed the 15 minutes lambda execution limit.
3.2.2. Data consistency: Reads and writes must be executed in FIFO order per stream and only a single read/write flow per stream may be performed simultaneously.
3.2.3. Concurrency control: We must be able to keep the total number of simultaneous reads and writes across all streams to independent and customizable limits.
3.2.4. Failure tolerance / Disaster Recovery: The solution should tolerate temporary outages but ultimately suspend processing of failing streams until resolution. Ingress of inbound events for such streams should continue.
3.2.5. Optimal resource utilization: if processing capacity is available it should be used ASAP. If we are not efficient and don’t process messages within a few hours in the worst cases, we lose the benefit of real-time over scheduled sync. We should sync almost immediately most of the time.
4. Infrastructure and capabilities
What have we got in our toolbox to overcome the challenges?
The basic tools of the trade are API Gateway, SQS, Dynamo, S3 and Lambdas. Armed with TypeScript and the serverless framework, off we go. The details are again a topic for another writeup, but here's an outline as relevant for the implied requirements in the previous section.
4.1 Flow consistency
AWS State machines entered the picture early to handle flows that cross the duration limits of a single lambda and to provide solid execution guarantees. Two state machines were planned - one for the inbound and one for the outbound flows (see the illustrations in section 3.1).
This contributed to the need for a concurrency control mechanism.
4.2 Data consistency
In section 3.1 we discussed how racing sync jobs can overwrite new data with old data or even cause a deadlock in Oracle.
Can we use an SQS’ FIFO GroupId to prevent concurrent execution on the same stream?
On its surface, yes - in FIFO mode, SQS will invoke lambdas in the correct order per GroupId (=stream in our case) and limit the number of parallel instances to your liking. But does it help prevent concurrent execution of state machines? The answer is no. As soon as the invoking lambda calls the state machine, its job is done and SQS will invoke the next lambda instance to process the next batch. There are a number of relevant discussions online, such as this.
4.3 Concurrency control
On top of per-stream exclusivity, we must apply independent limits on the total concurrent reads from Salesforce and writes to Oracle.
Sounds like something for SQS or state machines?
Since the flows include state machines, SQS cannot help us control their concurrency, as outlined in the previous point 4.2.
Why state machines can’t help is a bit more intricate. There are tens of thousands of streams and maximum simultaneous state machine executions are limited by 10K so we can’t have a separate execution per stream. The count of active state machines via AWS API provides no consistency guarantees. State Machine’s internal parallel execution is that - parallel execution that would batch independent concurrent flows for no reason. In any case, state machines run lambdas which are limited by 1000 concurrent executions per region per account.
We resort to a custom implementation of the semaphore concept to provide consistency guarantees for counting concurrent flows.
4.4 Failure tolerance
Based on the guarantees of AWS services involved we can expect to have a stable flow except the inevitable occasional outage in one of the parties involved. We implement error notifications where exceptions are expected, and stop stream processing in such cases. We also plan for the Service Operation Procedure to include instructions for reconciliation that support staff can understand and use.
5. The solution
Without going into too much detail, the solution included multiple SQS, two state machines and other cogwheels. The requirements changed and crystallized in a very agile manner, focus was shifted around and weeks went by, but against all odds the pipeline was eventually working.
Since the discussion above is full of little implementation details and design decisions, I’m going to skip right to the final points. Going deeper into the solution could be done another time. I just hope this far I’m still ok with respect to my NDA.
6. Scrutiny and alternative approaches
Having read this far you’ve likely considered whether the path taken was optimal.
The amount of doubt cast on the solution by the project owner was the highest I’ve experienced of all projects for this client. It’s understandable judging by the scope, the associated organizational and financial impact and the weight of responsibility.
As a result, the solution was subject to multiple (almost regular) reviews by internal architecture authorities, teams of colleagues involved with somewhat similar integration tasks, and AWS’ own consultancy teams. Within these limits it may be considered peer-reviewed. Since no better approach was devised we kept going ahead to materialize the effort and investment.
Below is a list of alternatives considered and the reasons for not choosing them:
-
AWS AppFlow Despite its attractive point-and-click value proposition, it lacked/lacks both integration to Oracle and sufficient extension options to implement it ourselves. The best we heard from AWS folks was that we could wait for something they had in the works and could provide in a few months.
Noone wanted to wait for a few months. -
AWS Glue Another powerful contendant, Glue was close to being preferred. The team was reluctant to switch to Python (the project was planned as TypeScript-based and had a mix of TS/ex-Java developers), but this would ultimately not be a show stopper. What was though is the slow cold starts of Glue containers which would dash any aspirations for near real-time communication.
-
A traditional integration platform The customer was running away from two of these. To my best knowledge, they are not going back.
-
An IPaaS While there were ongoing discussions of the need to have a shared modern platform, it’s easy (hard?) to imagine how long the decision-making and procurement takes. Definitely outside the scope of this project.
-
ECS/Fargate could help address some of the concerns that emerged purely from the serverless-based approach (15 minutes lambda execution limit standing out). Containers expect a fleet of EC2s - that immediately crosses the boundary of pure serverless, and requires more exception approvals. They are not a go-to solution in the given environment and would present new challenges such as long cold starts and new unknown unknowns, while not inherently solving e.g. concurrent access.
There are always more products that could make a fit with sufficient tweaking. However the team generally tended to prefer standard practices applied across similar teams in the organization. A big part of these practices is to get away with AWS services that are approved by default or are easy to get an exception for. Anything else slows development and must be strongly justified, or else it will eventually cause raised eyebrows.
Ultimately, all reviews ended up concluding that the solution’s direction is the best way forward given the explicit and implicit requirements, time limitations and other circumstances.
7. Conclusion and a generalization
Most of the challenges in this project are fairly typical and can be addressed by the serverless toolbox. However, there are recurring themes requiring a more advanced solution.
- Near real-time processing
- 15 minutes execution limit on lambda
- Preventing overlapping flows from simultaneous execution
- Observing concurrency limits
- Avoiding idle capacity when there is work to do
Consider the following illustration:
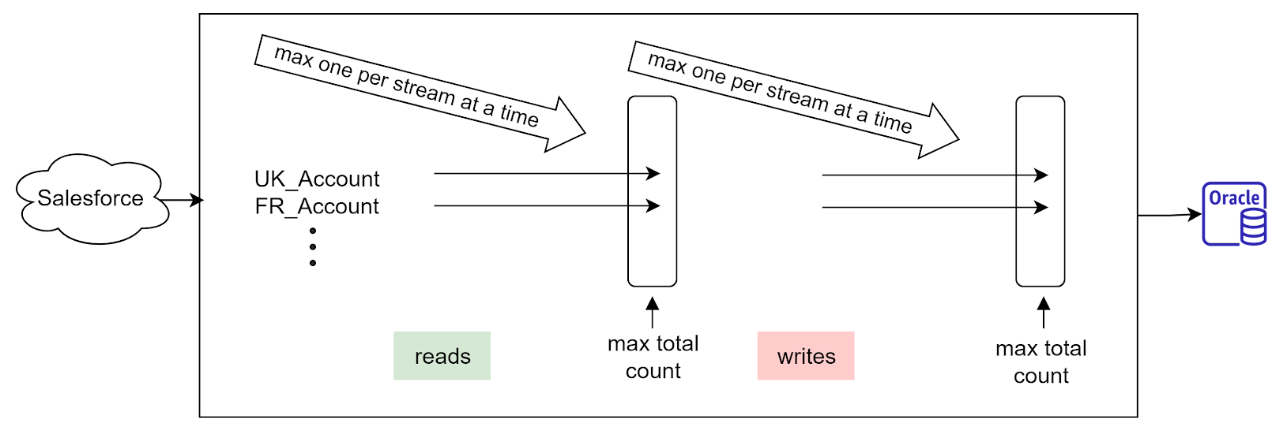
Fig 5. Horizontal and vertical concurrency limits. Vertically, reads are limited by max connections to SalesForce, Writes are limited by max connections to Oracle. Horizontally, only one synchronization may be run at a time per stream.
Requirements 2 and 3 imply concurrency limits represented horizontally and vertically in Fig 4. The need to occasionally go beyond the 15 minutes lambda execution limit is rendering SQS FIFO guarantees insufficient for resolution of concurrency requirements.
The solution in the project evolved to use a specific combination of SQS queues, DynamoDB tables for streams tracking and semaphores for managing concurrency of long tasks performed by the state machines and overall read/write concurrency limits.
Being focused on the project and repeatedly reminded that IT solutions are not the core of the business, I had no opportunity to realize what seemed like an obvious generalization that should solve all these points simultaneously. But I couldn't stop thinking it's possible and necessary.
This experience is one of multiple where concurrency was a concern that did not have a straightforward solution. There are tools for resolving concurrency but they are technology-specific, require complex maintenance, setting up clusters or all of these. There are techniques for solving concurrency in-house but any of them will distract the team from the core use case and will likely compromise on quality over delivery timelines.
8. WebSemaphore - summary
WebSemaphore is aimed to address concurrency management and efficient resource utilization over time in the context of distributed systems. Its simple API will help developers working on custom applications enable exclusive or concurrency-wise limited access to resources or isolate jobs. It can help amortize access to resources that are limited for technical or process reasons, for both ingress and egress scenarios and can facet entire APIs. All that without disrupting your stack or workflow.
It is the service I wish I had in the toolbox when architecting and implementing the solution presented in this article. The many sprints it took to comply with the requirements could have been invested in use-case related activities rather than infrastructure. I do hope it will help your company deal with concurrency easily and at scale.
WebSemaphore is in beta and we are actively looking for pilot customers to try out all of the features. As an early partner you will have the exclusive opportunity to influence product priorities as we make it fit your needs.
`